

企業データの法則性
CARPES手法によって企業データ特有の、さまざまな法則性が明らかになります。

企業データの一般的な法則性(詳細は各企業ごとに異なります)
ランキングデータ

時系列データ

ネットワークデータ

◆パレートの法則(80対20の法則)
◆ロングテール
◆大きな格差
◆対数グラフで出現する縛り棒
◆縛り棒の平行移動
◆縛り棒の回転
◆最高桁数字は”1”が最も多い
◆・・・
◆千鳥足で変動する時系列データ
◆今期の値=前期の値 × 成長率
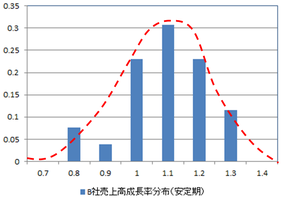
◆成長率はほぼベル型カーブ
◆成長率の一寸先は闇
◆成長率は一定の範囲で変動
◆年変動と月変動は似たパターン
◆ある程度先まで予測が可能
◆・・・
◆重層構造のネットワーク
◆少数のハブの存在
◆結合と反発が作る大きな格差
◆ロングテール
◆世界はせまい(6次の隔たり)
◆弱い紐帯の法則
◆”創発”の源泉
◆・・・


詳細な説明はコンサルティングで行います。ここに80対20の法則例を記載します。
法則性の詳細例 : 80対20の法則
80対20の法則は、図PL-1のような例えで説明される有名な経験則です。

図PL-1 80対20の法則例
その一般的な解釈は図PL-2のようになります。すなわち、全体の投入エネルギー(マンパワーなど)の、わずか20%で全体の80%の効果を得る、というものです。

図PL-2 80対20の一般的な解釈
この法則は、19世紀後期のイタリアの経済学者パレートによって発見されたので、パレートの法則とも言われます。パレートは当時イタリアのある都市の富豪の所得を研究していてこの法則を発見しました。
ここではパレートの例に倣って、日本の富豪の資産データで追体験することにします。図PL-3は2015年の日本の富豪トップ50人の資産額ランキングです。元データはForbs社からの引用です。トップはF社のYさんで資産額なんと2.5兆円。2位はS社のSさんで以下5位までの方々は1兆円を超えています。パレートも当時このようなデータを眺めてため息をついていたことでしょう。

図PL-3 日本の富豪Top50の資産額ランキング
上記グラフに、トップからの累積資産額を追記したものが図PL-4で、パレート図といわれます。

図PL-4 日本の富豪Top50の資産額ランキング パレート図
トップから順に累積しているので当然ですが、この例では上位14人(28%→約30%)の資産額合計の約70%を占めていることがわかります。

図PL-5 日本の富豪Top50の資産額ランキング 法則性
このような特徴に気づいたパレートは、さらに幅広い研究を行い、どの都市でも、国でも、富豪の所得は皆同じような関係が成り立っていることを突き止めました(1896年)。この関係は後に広く使われるようになってから80対20の法則と呼ばれることになりますが、データによって60対40や85対15などの関係になります。

図PL-6 日本の富豪Top50の資産額ランキング 法則性 80対20
この法則は非常に興味深い法則ですが、当時は使い方がわからなかったためか、しばらく忘れ去られていました。
パレートの発見から半世紀後の1949年にアメリカの言語学者ジップが文学の世界で似た法則を発表し、ジップの法則と呼ばれています。以下ジップの追体験をしたいと思います。図PL-7はヘミングウェイ作”老人と海”の要約版(出典Wipipedia)です。この文は約600語の単語で構成されています。では、どの単語の使用頻度が最も高いか?というクイズです。

図PL-7 ヘミングウェイ ”老人と海”要約

図PL-8 ヘミングウェイ ”老人と海”要約 theの頻度
この文章で最も多く使われている単語は”the”で、60回使われています。全体の約10%は”the”ということになります。英語圏ではtheが最も多いのは常識で驚かないでしょうが、ジップはユリシーズという文学書に出て来る約26万語を全て調べ上げ、その結果図PL-9のような特徴を発見しました(横軸は使用頻度の多い順位)。しかも、使用頻度1000位あたりまで、ほぼ同じ傾向で、使用頻度N位の単語の使用頻度はトップの単語(the)のN分の1である、という驚くべき法則性だったのです。ちなみに
10位:i(アイ)、20位:or、100位:say、200位:really、1000位:qualityとなっており(ユリシーズの場合)、qualityはtheの約1/1000の使用頻度となっています。

図PL-9 ジップの法則(ユリシーズの場合)
ジップは言語学者であるとともに心理学者でもあったためか、その理由を考えました。そして「労力最小化の法則」という原理を発見しました。すなわち、全体の結果は投入したエネルギーが最小になるような分布になる(理由は分からないが)・・・・ということです。英語というのは、このようなランキングの単語の組みあわせで(最小のエネルギーで)最大の意味を伝えるように出来ている、ということになります。英語だけでなく、あらゆる言語が同様の原理を持っているということになります。
ジップに約2年遅れて、アメリカのジュランという学者は、やはり理由はわからないものの機械の故障原因の頻度にパレートやジップの法則と同様な傾向があることを見出しました。これを品質管理に応用して多大な成果をあげたのです。(図PL-10 品質管理)

図PL-10 品質管理
ここまでの説明で
◆資産、言語、故障と、種類の異なるさまざまなランキングデータに似た傾向が現れる。
◆根底に共通の原理が働いているのではないか?
という気づきや疑問が出てくるはずです。

図PL-11 根底にあるもの?


図PL-12 複雑系のメカニズムが作る80対20の法則
根底にあるのは複雑系というもののメカニズムです。